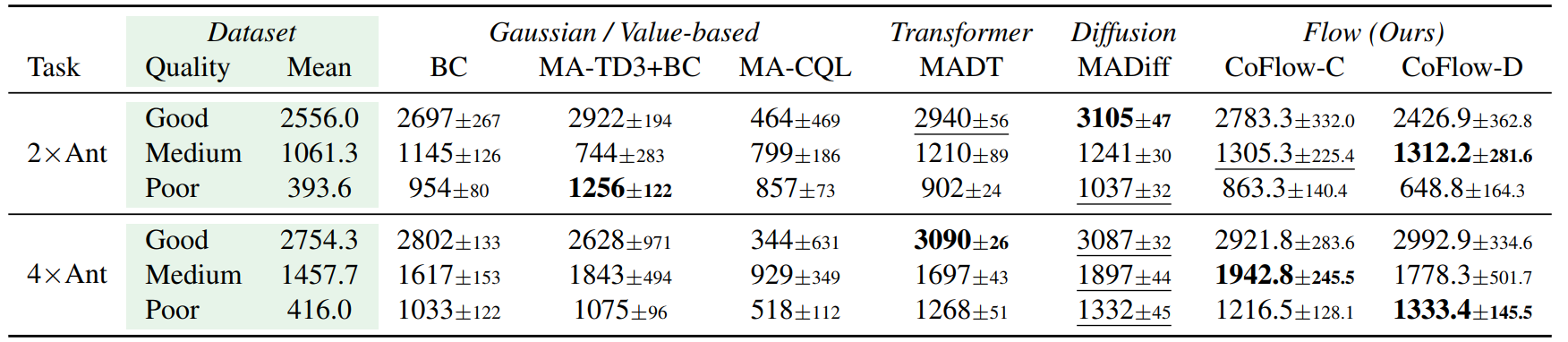
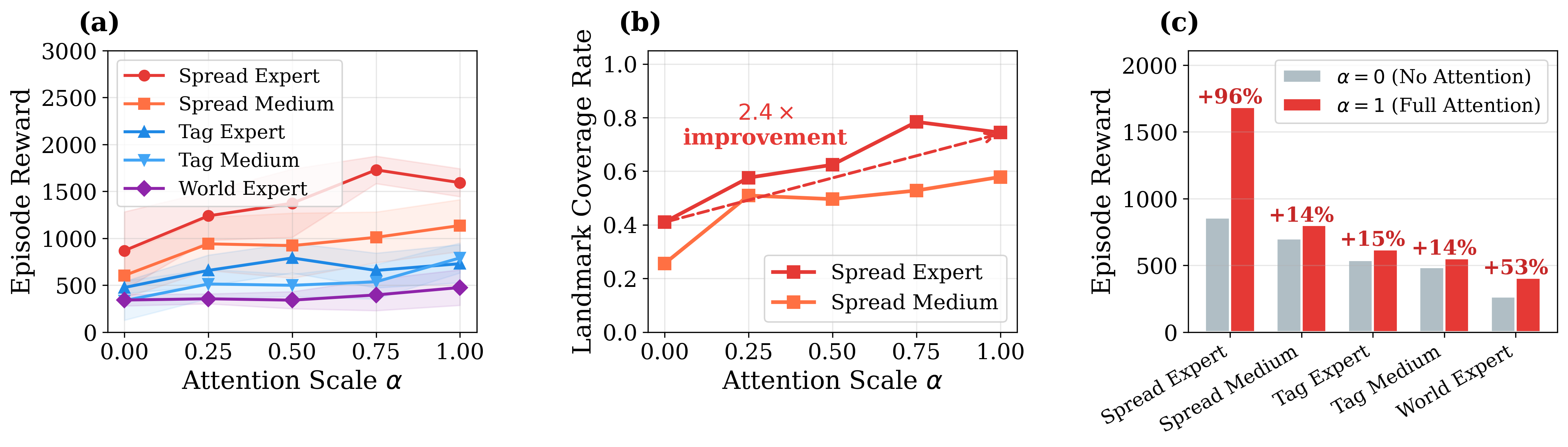
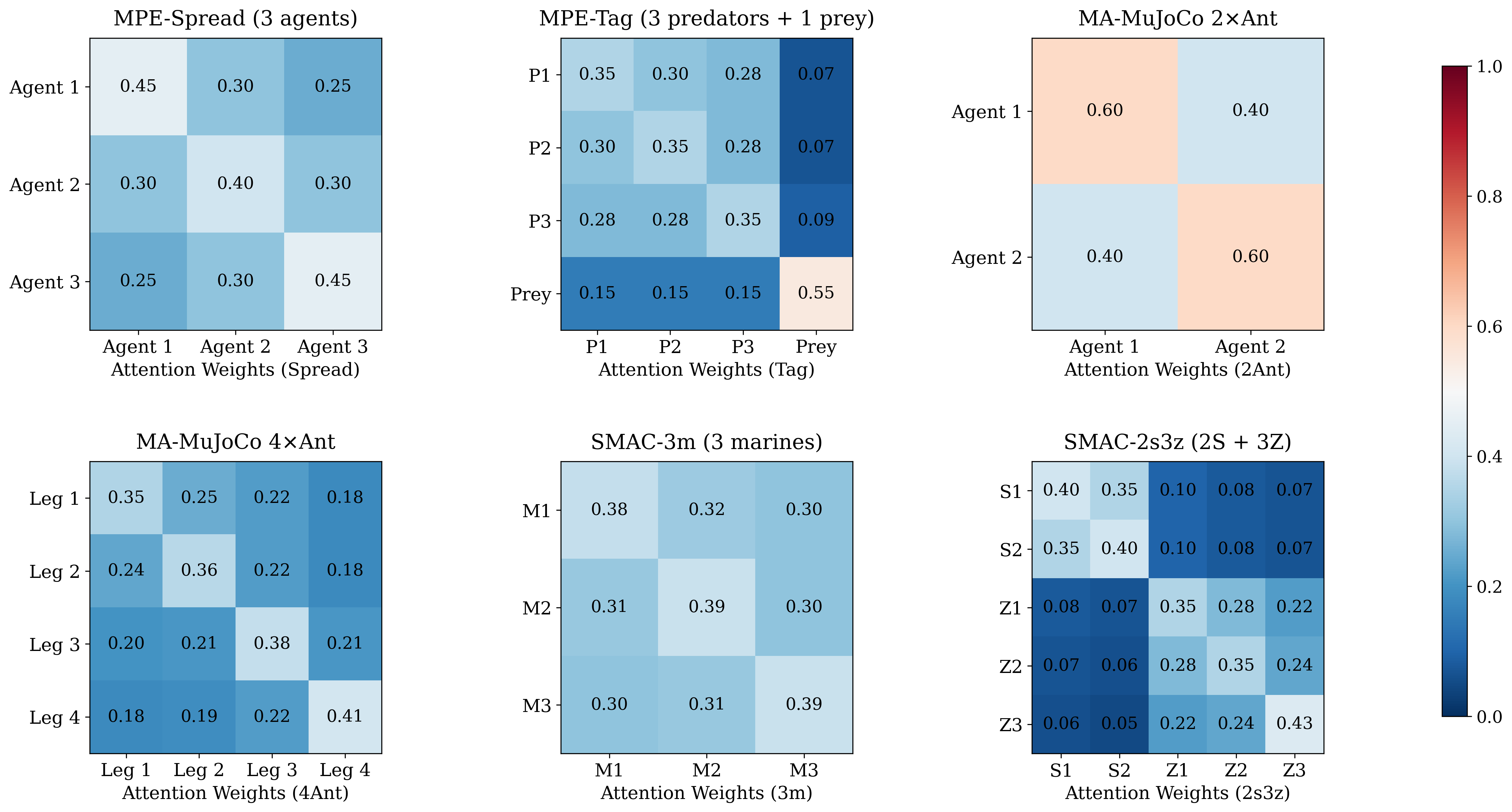
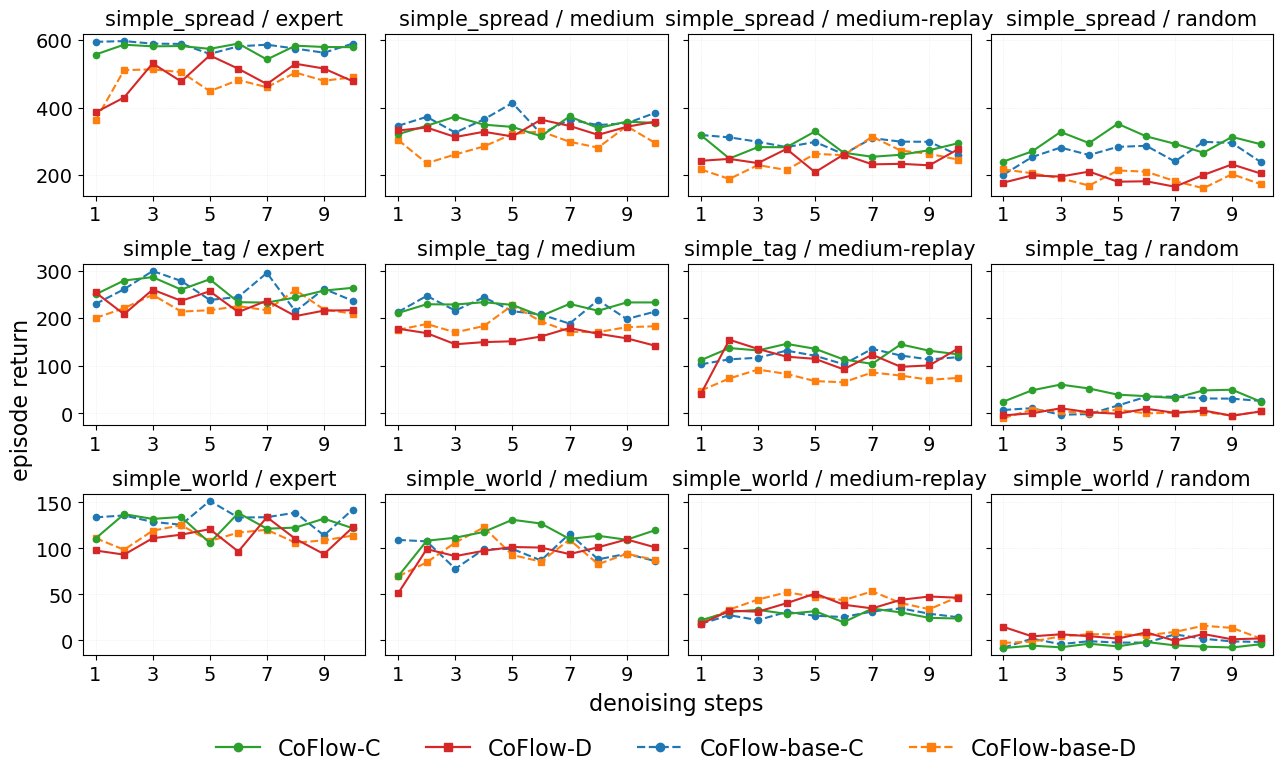
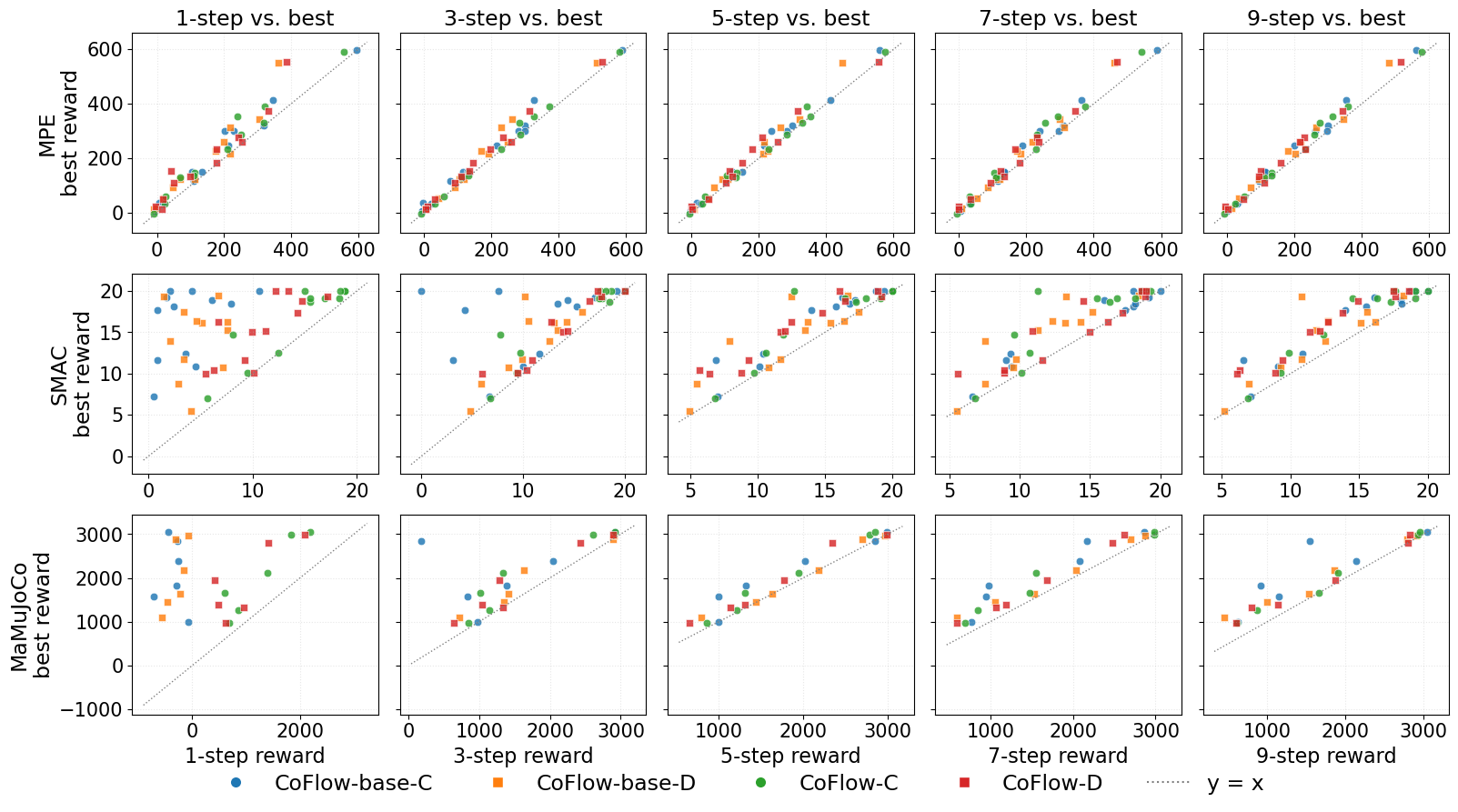
RQ1: Can CoFlow match or exceed strong offline MARL baselines across continuous and discrete benchmarks?
Answer: Yes. CoFlow-C is best on most table entries, while CoFlow-D remains competitive under decentralized execution. The gains are most visible on coordination-heavy MPE tasks.
Main Result Tables
Full result tables are inserted as screenshots. Bold marks the best method in each row, underline marks the second-best method, and tables scroll horizontally on narrow screens.
Table 1: MPE
Continuous-action cooperative benchmark on Spread, Tag, and World.
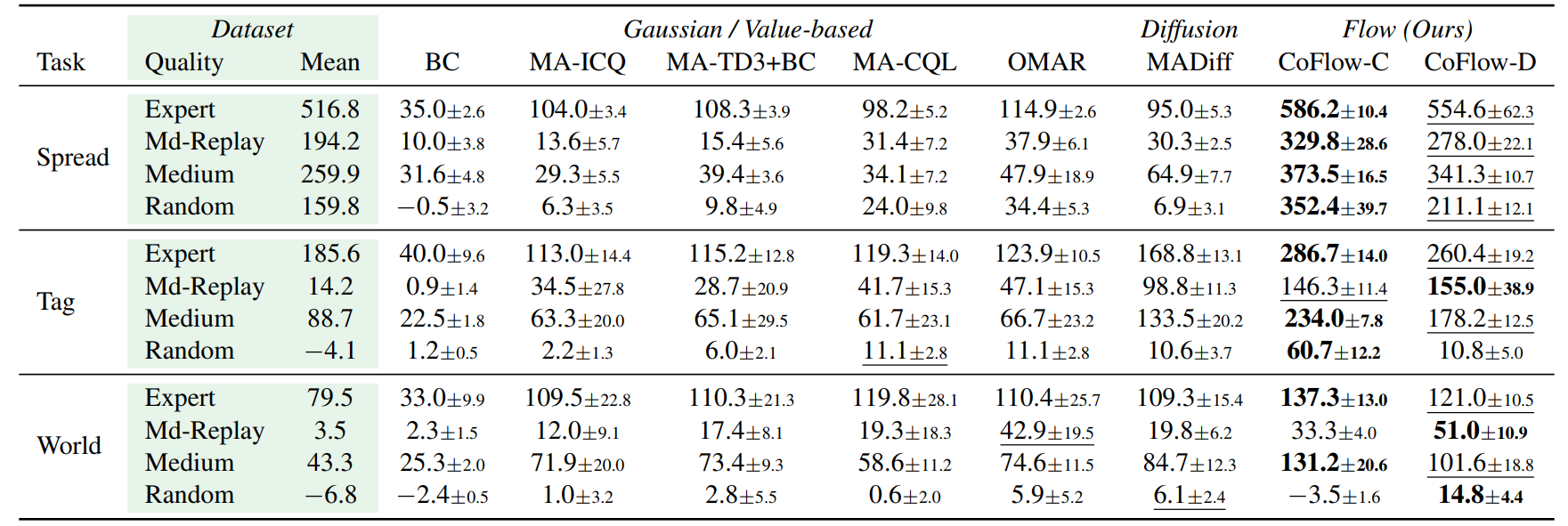
Table 2: SMAC
Discrete-action StarCraft benchmark with partial observability.
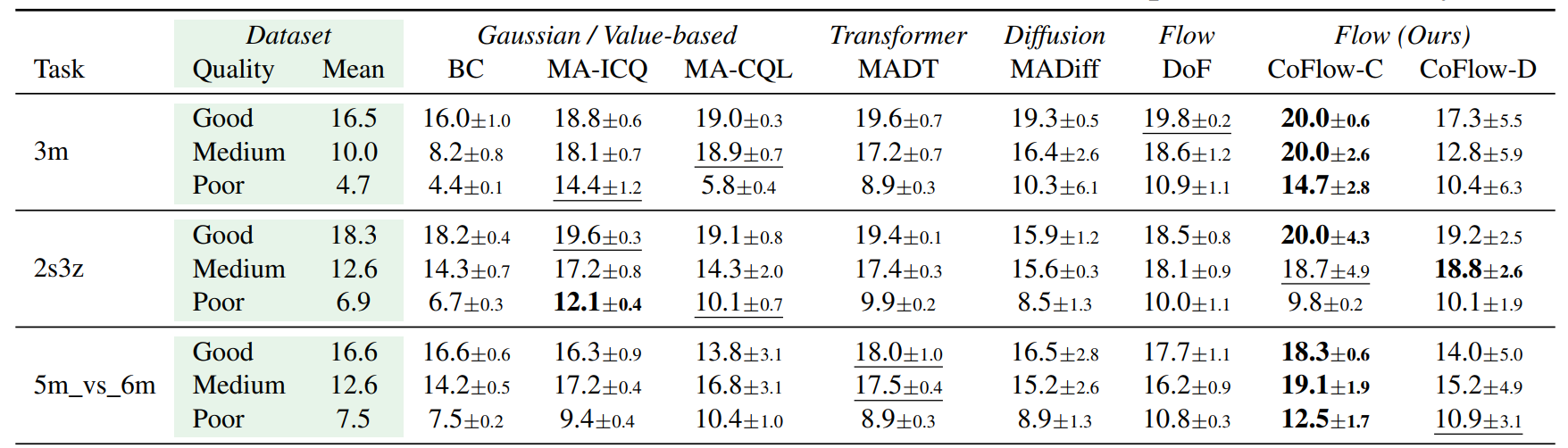
Table 3: MA-MuJoCo
Continuous-action locomotion benchmark on 2xAnt and 4xAnt.